How I Review Laravel Pull Requests
A teammate sent me a small PR last quarter to clean up a user index endpoint. The original code did User::with('orders', 'subscription', 'lastInvoice')->paginate(50). The teammate had noticed that lastInvoice was only used by a tiny badge on the page and refactored it into a separate conditional query. The PR was a model of clean code: smaller controller, decent naming, extracted helpers. Tests passed. I approved it inside ten minutes. The diff was small and the change was sensible.
Three weeks later, the admin page started timing out for customers with large tenants. The query log told the whole story. The new code was running select * from invoices where user_id = ? order by created_at desc limit 1 once per row, fifty times per page render. The original with('lastInvoice') had been a hasOne constraint, eager loaded in a single query. The refactor turned it into an N+1.
The code was clean. The refactor was reasonable. The reviewer (me) had looked at the structure and not at the data access pattern. Nothing in the diff was bad code. The bad part was the diff itself, and I had not asked the question that would have caught it. I had reviewed the code. I had not reviewed the risk.
That incident changed how I review pull requests. Not because the bug was unusual, but because the path from "approve" to "incident" was so short and so quiet. The diff was small. The author was careful. The tests passed. The review looked at the wrong layer of the change. Every part of the system did its job, and the system still produced the wrong outcome a few weeks later. This article is the discipline I built afterwards: how I actually read a Laravel pull request before approving it.
Table of Contents
- The Biggest Mistake Developers Make During Code Reviews
- What I Look At First
- My Security Review Checklist
- My Performance Review Checklist
- My Maintainability Review Checklist
- Queue, Job, and Event Review
- Database and Migration Review
- Deployment and Operational Review
- Common Red Flags I See
- A Real PR Review Example
- What Changed As I Became More Experienced
- Closing Thoughts
The Biggest Mistake Developers Make During Code Reviews
Most code reviews I see are reading exercises. The reviewer scrolls through the diff, comments on formatting, suggests a better variable name, flags an architectural preference, and approves. The author addresses the comments, gets a green check, and merges. Everyone has done their job.
Almost none of that work catches the bugs that hurt in production. The bugs that hurt in production are not in the formatting. They are in the assumptions: the assumption that the Eloquent relationship will not be hit in a loop, that the Policy will scope to the right tenant, that the queued Listener will not run twice, that the migration will not lock a hot table, that the cached value is still valid after the deploy. None of those assumptions show up as red squiggles in the diff view.
What changed for me as I got more years in production is the question I ask first. I no longer read a PR to evaluate whether the code is well written. I read it to figure out what it can break. I am not reviewing code. I am reviewing risk. The code is the vehicle. The risk is the thing I actually have to decide about.
What I Look At First
Before I read a single line of code, I want to answer five questions. Most of them are not in the diff. They are in the PR description, the linked ticket, the commit history, or my own knowledge of the system.
- What problem is this solving? If the PR description does not say, I ask. A change without a stated reason is a change I cannot evaluate, because I cannot tell whether the implementation matches the intent.
- What production systems does it touch? Eloquent models on hot tables, Policies, Jobs, Listeners, the scheduler, third party SDKs, anything that talks to Stripe or AWS or a webhook endpoint. Every touched surface is a place a bug can land.
- What is the blast radius if it fails? A formatting tweak to a Blade view is one thing. A change to
OrderPolicy@viewis another. Knowing the blast radius decides how carefully I read. - Is the change reversible? A code-only change is easy to roll back. A change that ships a destructive migration is not. Destructive changes get more eyes and a written rollback plan before I look at the implementation.
- Does the implementation match the requirements? The ticket might say "filter cancelled orders out of the dashboard." The code might also filter out refunded orders, because the author conflated the two states. Mismatch between intent and code is the most common substantive review finding I leave.
Those five questions take maybe two minutes. They tell me how to read the rest of the PR. A small change in a low-risk area gets a fast read. A change in auth, billing, or anything with a migration gets a slow one.
My Security Review Checklist
The questions I run through on any PR that touches authorization or input handling.
- Are Policies and Gates updated alongside the new routes or actions? A new Controller method without a corresponding Policy check is an authorization bypass waiting to be found.
- Does the Policy scope correctly to the user's current tenant or team? Multi-tenant apps live and die by this question.
- Are Sanctum token abilities being respected on the new endpoint? Or is the middleware just checking that the token exists?
- Is the Form Request validating every field the controller uses? Mass assignment vulnerabilities still happen when the model has
$guarded = []and the controller passes$request->all()tocreate. - For file uploads: extension validation, MIME validation, size cap, storage path that does not allow traversal, no executable assumed safe.
- Are sensitive fields excluded from API Resources? It is surprisingly easy to add a new model attribute and forget that the API Resource is serializing the whole model.
- Anywhere the code accepts a record ID, is the access check happening before the work? Route model binding does not authorize on its own. The Policy does.
Production story: the Policy that crossed tenants
A PR added a "shared with me" feature. Documents could be shared with users on the same team through a document_shares table. The DocumentPolicy@view method was updated to return true if the user owned the document or if the user appeared in document_shares for it.
The PR shipped. Two days later, a customer reported they could see a document on Team B that had been shared with them while they were on Team A. The Policy update was checking "is this user in document_shares" without also scoping to the user's current team. A user on multiple teams could see shared documents across the team boundary, which is exactly what the tenant isolation model is supposed to prevent.
The fix was one line: ->where('team_id', auth()->user()->current_team_id). The cost of finding it after deploy was a customer trust conversation and a security incident write-up. The cost of catching it in review would have been asking one question: what tenant boundary is this change crossing? The same point I made in the authentication and authorization post applies in review: every authorization change has to be evaluated against the boundary it is supposed to enforce, not just the rule it adds.
My Performance Review Checklist
I do not optimize every PR. I look hard at the ones that touch hot paths: list pages, dashboards, anything in the public API, anything inside a request loop.
- N+1 patterns. Any new
foreachover an Eloquent collection where the body accesses a relation. Any place a teammate "extracted" a query and quietly dropped awith(). Any Resource that loads a relation per item. - Missing eager loads. When a relation is accessed in a Blade view or an API Resource, the controller must eager load it. Lazy loading inside a view is the silent N+1 generator.
- Index awareness. A new
where('email', '?')filter against a million-row table needs an index. The migration should add it. The PR should mention it. - Query count per request. A new endpoint that fires 30 queries to render is doing something wrong. Telescope or Debugbar will show this on staging. The reviewer should ask whether the author checked.
- Collection misuse. Calling
Model::all()and then filtering in PHP. Loading 50,000 rows into memory tosuma column when the database can do it. - Cache implications. A new cache key that does not include the tenant, the user, or a relevant scope. A cache that is never invalidated when its underlying data changes. A Cache::remember call that runs an expensive query inside the closure with no rate limit when the cache misses.
- Expensive operations in middleware. A middleware that loads the user's permissions, runs a Policy check, and hits a third party API on every request can drag the whole app down. Middleware runs on every request that matches.
Production story: the aggregate that did not aggregate
A teammate refactored a "total revenue this quarter" widget on the admin dashboard. The original code was a single database aggregate: Order::where('team_id', $teamId)->whereBetween('paid_at', [...])->sum('amount_cents'). They wanted to add a "skip refunded orders" filter that already lived as a method on the Order model, so they switched to ...->get()->filter(fn ($o) => ! $o->wasRefunded())->sum('amount_cents'). Cleaner looking, easier to read, and the new filter was reusable. Tests passed on the development fixture (a few hundred orders) and on staging (a few thousand).
The first customer to hit the new code in production had 2.4 million orders in the date range. The endpoint loaded every row into memory, hydrated each one into an Eloquent model, ran the PHP filter over the entire collection, and summed an attribute. The worker hit its memory limit and the request returned a 500. The dashboard had been a single fast query. The refactor turned it into a memory crash.
The fix was to push the filter back into the SQL: ->whereNull('refunded_at')->sum('amount_cents'). The database does aggregates without materializing rows into PHP, and that property does not change as the data grows. A PHP collection does the same work in linear time and memory. The two layers are not interchangeable. The database stays cheap as data grows; the application server does not.
The review-time question that would have caught it: how does this code behave when the dataset is ten times larger than the fixture? If the answer involves loading every row into memory, the implementation is not done.
The deeper background on each of these lives in the performance post. In review, the question is simpler: does this PR add work to a hot path, and has the author measured?
My Maintainability Review Checklist
Maintainability problems are the ones that do not show up for six months. They are also the cheapest to fix at review time.
- Hidden business logic. A model observer that decides whether to send an invoice. A Listener that mutates pricing. Operational side effects in observers are fine; business rules are not.
- Fat controllers. A controller method longer than maybe forty lines is doing more than one job. Push it into an Action, a Service, or split the responsibility along the request boundary.
- Naming that hides intent.
OrderManager,OrderHelper,OrderProcessor. If the class name does not tell me what it does, the author has not finished deciding what it does. - Responsibility creep. A class that started doing one thing and is being asked to do two. Splitting at the right boundary is cheaper now than later.
- Cleverness. A one-line solution that needs a paragraph of explanation. The clever version is the one the next engineer will not understand and will rewrite incorrectly.
The question I keep in the back of my head: will somebody (including me) understand this in six months? The change cost framing from the maintainability post and the architectural shape from the structure post both apply at review time. Consistency with the rest of the codebase wins over local cleverness almost every time.
Queue, Job, and Event Review
Anything that touches queues, Jobs, Listeners, or Notifications gets a dedicated set of questions, because the failure modes are different from synchronous code.
- What happens if this runs twice? Retries are real. Webhook duplicates are real. The job has to be safe on a second run.
- What happens if it fails? Is there a retry policy with backoff? Is the failure recoverable? Is there a path to inspect
failed_jobsand replay? - What happens if the queue backs up? Does this job sit on the same queue as user-facing emails, or does it have its own lane?
- Is the payload small? Passing an Eloquent model serializes the whole object. Passing an ID and refetching is safer for state-sensitive jobs.
- Does the Listener need
ShouldQueue? A synchronous Listener inside a request blocks the response. A queued one does not, but introduces all the async failure modes. - Does Horizon balance correctly with the new job mix? A new high-volume job can starve other supervisors if the balance strategy was sized for a different workload.
Production story: the Listener that fired twice
A PR added a Listener for the OrderPaid event. The Listener sent a thank-you email and credited the customer's referral wallet by $5. It correctly implemented ShouldQueue. It did not implement any idempotency guard or ShouldBeUnique.
In normal operation the code was fine. Then Stripe delivered the same payment-succeeded webhook twice during a transient timeout retry. The webhook controller dispatched OrderPaid twice. The Listener ran twice. The customer received two thank-you emails twenty seconds apart and an extra $5 referral credit they had not earned. Multiply that by a few hundred customers over a busy weekend and the support ticket queue tells you something is wrong.
The PR review had focused on the Listener's logic (correct), the email template (clean), the wallet calculation (right amount). Nobody had asked the only question that mattered: what happens if this fires twice? The Stripe webhook controller had its own idempotency guard (a processed_events table). The new Listener had not inherited it, because events do not pass that context along. The fix was a deterministic claim on the order_id before crediting, plus ShouldBeUnique on the Listener with a uniqueId tied to the order. The queues and jobs post covers the application-side discipline; in review, the discipline is the question.
Database and Migration Review
Migration PRs are the most dangerous PRs you can review. They are the only ones that can take the application down while every other system is healthy.
- Hot table check. Is the migration against a table over a few million rows? If yes, the simple ALTER is not safe.
- Locking behavior. Adding a NOT NULL column with a default rewrites every row on most MySQL versions. Adding a foreign key constraint revalidates the entire table. Both will lock writes for the duration.
- Backward compatibility. Does the new code in the same PR also drop usage of the old column? If yes, the schema and code changes need to be split across at least two releases.
- Rollback path. Is the
down()method real and tested, or is it a stub somebody wrote to satisfy the linter? - Expand and contract. For any non-trivial schema change, is the change shipping as add-nullable, backfill, switch-read, drop-old across multiple deploys, or as one big rewrite that cannot be reversed?
The patterns that make this approach work are the ones in the database schema post. The deployment discipline that makes it safe is in the deployment post. The review-time discipline is to ask, on every migration PR, what is the worst case if this migration is wrong? If the worst case is data loss, the PR needs more than two engineers on it.
Deployment and Operational Review
Most code reviews stop at code. The application does not. A PR that ships safely as a code change can still break in production if the operational surface around it has shifted.
Some of the worst production incidents are not caused by bad code. They are caused by code that cannot be deployed safely. The diff is correct in isolation. The deploy is correct in isolation. The pair is not. Schema changes coupled to application changes that drop usage of the old shape, queue payload changes without a two-phase compatibility window, new environment variables that are not synced to every server, cache rebuild assumptions that hold on web but not on the worker fleet. Each of these is invisible in a syntax-level review and very visible at 2 AM. The deployment post walks through what each one looks like in practice; in review, the discipline is asking which of those traps the PR is opening.
The questions I work through:
- Can this be deployed safely? Does it require a specific deploy order (migration first, then code), or can it land in any order?
- Does it require a worker restart? If the PR changes a Job payload shape, the workers must restart and the dispatcher needs the two-phase compatibility plan.
- Does it require a cache rebuild? A new entry in
config/services.phpor a closure-based route addition can breakconfig:cacheorroute:cacheif the rebuild step is skipped. - Does it require an environment variable? Has the env variable been added on every server, in CI, in the secret manager, in the deployment hook, and documented?
- Does it require a new queue or a Horizon supervisor change? Horizon's configuration needs to ship in the same release that adds the new queue.
- Can it be rolled back? If a forward fix is the only path back, the rollback plan needs to say that explicitly.
- Does it change scheduled work? The cron-driven scheduler picks up new code, but the Jobs it dispatches need the same two-phase thinking.
A surprising number of "easy" PRs are not easy once you add the operational layer. Asking these questions at review time is much cheaper than asking them during an incident.
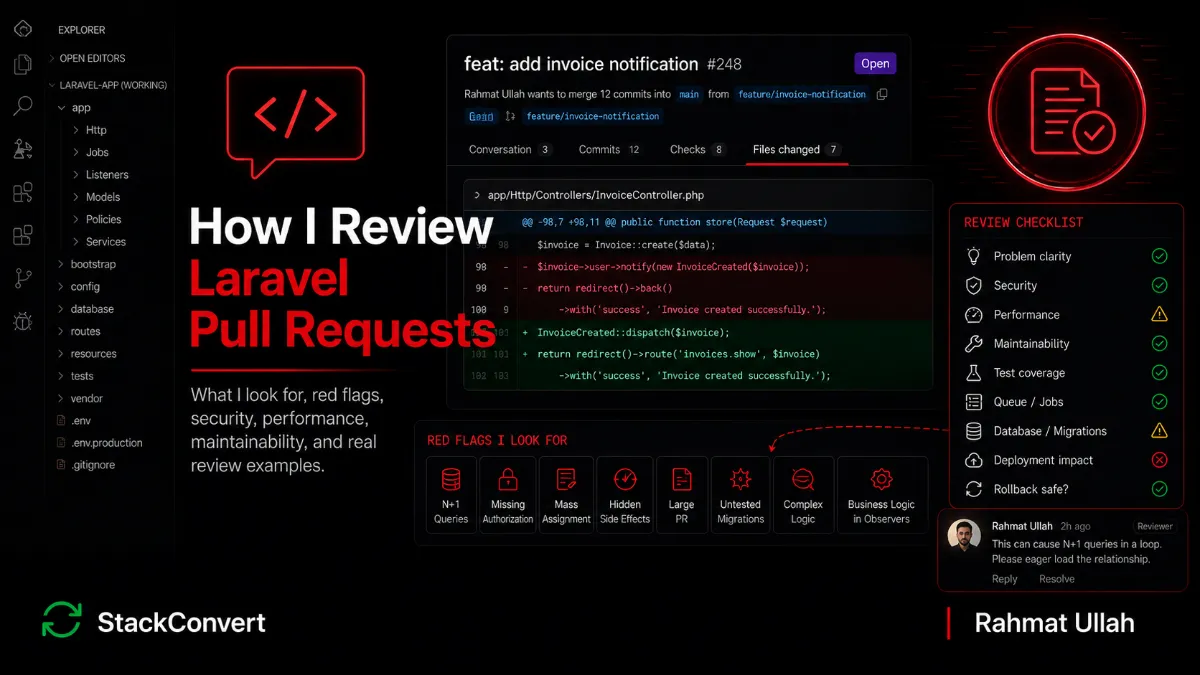
Common Red Flags I See
- The 4,000-line PR. Nobody reviews this carefully. The author knows it. The reviewer knows it. The approval is theater. Send it back and ask for the PR to be split.
- Hidden side effects. An innocent-looking
$order->save()that triggers three observers, two events, four cache invalidations, and a recalculation on a totals column. - Cache keys missing tenant or user scope. A new
Cache::remember('dashboard.recent-orders', ...)without a tenant prefix is a multi-tenant data leak waiting to happen. The global scope on the model runs at query time. The cache layer does not run scopes; it returns the previously cached value verbatim. - New observers attached to critical models without documenting side effects. The next engineer who reads the controller will not see the observer. Operational use of observers is fine only if the team can answer, in one sentence, what an
$order->save()actually triggers. - Global scopes added without checking downstream queries. A new global scope on
Usercan quietly break the admin reporting query, the export job, and the analytics dashboard, in ways that do not throw exceptions. They just return the wrong rows. - Feature flags introduced without a cleanup plan. The flag will outlive the feature. Every flag that does not have a removal date becomes permanent dead code that has to be read on every traversal of the file.
- Business logic in observers. Operational side effects in observers are fine. Pricing rules, eligibility checks, or refund logic in an observer are a future incident.
- Long event chains. Event A fires Listener B, which dispatches Job C, which fires Event D, which dispatches Job E. Two hops is fine. Five is a debugging nightmare nobody can draw on a whiteboard.
- Generic service classes.
OrderServicewith twelve unrelated methods. A class that does everything is a class nobody owns. - Untested migrations. A migration with no rollback verification, no record of being run against a representative dataset, and no plan for what happens if it fails midway.
- Clever one-liners. A regex that needs a comment. A higher-order chain that fits the line but takes ten minutes to read. The clever version always loses to the boring version in maintainability terms.
- Premature abstractions. A new interface and three implementations introduced for a feature with one current caller. The right number of implementations is one until there are two.
- Catching
\Throwablewith an empty body. The error gets swallowed, the failure becomes silent, and the next on-call rotation has nothing to investigate when the customer reports a missing record.
A Real PR Review Example
Let me walk through what a review looks like in practice. The PR ships a new feature: send a notification to the customer when an invoice payment fails. Here is the rough shape of the diff:
- New
InvoicePaymentFailedevent, dispatched from the Stripe webhook controller when a charge fails. - New
NotifyCustomerOfFailedPaymentListener, implementingShouldQueue. - New
InvoicePaymentFailedNotificationclass, sending to mail, database, and Slack channels. - New migration adding
last_failure_atandlast_failure_reasoncolumns to theinvoicestable. - Updates to
InvoiceResourceexposing the new columns.
Here is the order I read the diff and the questions I leave as comments.
Intent. The PR description says "send the customer an email when their card fails." The implementation also sends a database notification and a Slack message. I ask: are the Slack and database channels in the requirements, or did the author add them speculatively? If speculatively, what is the cost of operating them?
Security. The Listener loads the Invoice by ID. Does the InvoiceResource respect tenant scoping when it serializes the new columns into the API? Does the Slack channel get the right team's Slack workspace, or does the default-channel fallback leak invoice details across customers? Is the database notification reachable from the customer's "notifications" page without authorization?
Queue behavior. The Listener is queued (correct). Is it idempotent? If Stripe retries the failed-payment webhook (which it does), the event fires twice, the Listener runs twice, the customer receives two emails and two Slack pings. I ask for a deterministic guard against the webhook event ID, and ShouldBeUnique on the Listener keyed off invoice ID. I also ask which queue it lands on. If it shares the default queue with user-facing emails, a backlog of failed payments could starve transactional mail for everyone.
Failure handling. If the mail send fails after the Slack send succeeds, the retry will send Slack again. I ask for the three-channel send to be split into separate Listeners (or for each channel's send to be guarded by a per-channel status flag), so a partial failure does not cascade into duplicate sends. The shape from the error handling post applies directly here.
Performance. The Notification template renders the customer's most recent five invoices in the email. Is that data eager loaded on the Notification's $invoice, or is it triggering five queries per send? On a busy Black Friday, the difference is real.
Migration. The invoices table has eight million rows on this product. Adding two nullable columns is light. Adding an index on last_failure_at for the dashboard query is heavier and should run outside the deploy. I ask the author to split the index into a separate migration with an explicit warning.
Deployment. The new Slack channel requires a webhook URL in .env. Has it been added to every environment, including queue workers? Will config:cache rebuild on deploy? The Listener restart is covered by the standard queue:restart step, but I confirm with the author that the rollout order is migration first, code second, cache rebuild third, workers fourth.
That is roughly fifteen minutes of review on what looked like a one-day PR. Half the comments will not result in changes. The ones that do are the ones that would have caused a real incident the week after launch.
What Changed As I Became More Experienced
Early in my career, the question I asked during reviews was does this code work? I would trace through the logic, check that the tests passed, suggest a cleaner name, and approve. That works fine for small applications that have never been on fire.
The question I ask now is what happens when this breaks? Not if. When. Production is the place where every assumption gets tested by traffic, time, retries, partial failures, and customers doing things nobody on the team predicted. A review that does not consider the failure modes is a review that has prepared the team to be surprised.
The other thing that changed is patience for the boring parts of a review. The expand-and-contract migration plan. The two-phase queue compatibility. The idempotency guard on the Listener. The Policy scoped to the tenant. None of those are interesting in isolation. All of them are the difference between a release that ships and a release that pages somebody at 2 AM.
Closing Thoughts
Pull requests are the cheapest place in the entire software lifecycle to prevent a production incident. A bug caught in review costs ten minutes. The same bug caught in production costs an incident response, a customer email, a post-mortem, and a forward-fix release. The economics are not even close.
Most production incidents I have worked on were not surprises. They were assumptions that had been visible in a PR for anyone who knew to ask. The N+1 in the eager-load refactor. The Policy that did not scope to the current tenant. The Listener that fired twice on a webhook retry. The migration that locked the orders table. Every one of them showed up in a diff that someone approved. The author was not wrong. The reviewer was not careless. The review was just focused on the wrong layer.
The shift that matters is small. Stop reading the diff to evaluate the code. Start reading the diff to evaluate the risk. The questions are different, the comments are different, the approvals are slower, and the on-call rotation gets quieter. That trade is worth it every single time.
The line between a junior reviewer and a senior one is shorter than it sounds. The junior asks whether the code works. The senior asks what happens when it does not. The first question has a single answer per PR. The second has a long list, and that list is the one production actually cares about. Time and incidents move you from one question to the other. Reading every diff with the second question in mind shortens the trip.
The sticky-note version: most production incidents begin long before production. Many begin the moment somebody clicks Approve.
What is the worst bug you ever approved in a PR?